2024 · 05 · 23
What I Learned From Designing AI Products With 1M+ Total Signups
For the last one and a half years, my cofounder Swee Kiat and I have designed several AI products.
Our first AI product is Pebblely, an AI product photography tool, which grew to a million signups in just seven months. We also built Vispunk, which had an AI image editor, an AI video generator, and an AI video editor. While Vispunk has not grown as much as we like, it also taught us a lot about designing AI experiences.
We were also forced to design as well as we could. Being bootstrapped for the last two years turned out to be a wonderful design constraint. We had to design intuitive interfaces that solve real problems (or nobody would pay for our products) and we had to work within our business constraints (or we would go bankrupt).
I have spent a lot of time banging my head against the wall, designing AI interfaces and experiences. To save you some headaches, here's what I have learned.
1. Text inputs vs visual inputs
This can and should be a series of blog posts on its own but it is important enough that I want to at least briefly discuss it here and mention it first.
One thing we have always found weird is how AI image generation is done mostly with only text. While the text-to-image technology was cool, using only text is very limiting for creating visual content. Getting the specific composition you want with only text is hard because we do not always know how to describe what we want and AI might not interpret our prompt as we do. You often have to keep trying different prompts or even the same prompt until you get what you want—much like rolling a dice. Midjourney users have tried writing paragraph-long prompts to generate specific compositions, which also does not feel ideal.
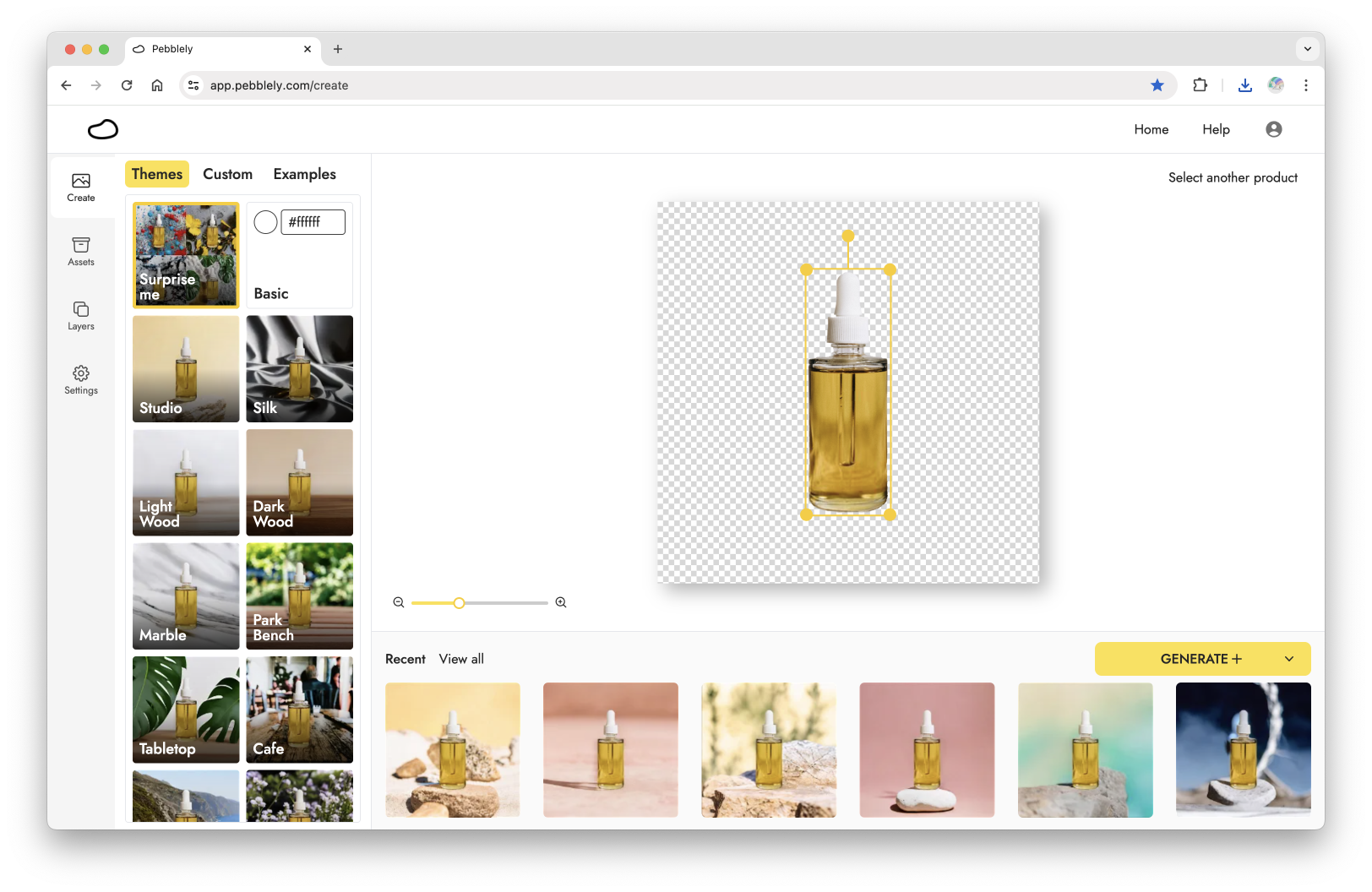
Visual creation should be visual. Instead of using only text, users should be able to visually control their inputs or visually show what they want. In Pebblely, you can move, resize, and rotate your product on a canvas before generating its background with AI. You can also use a reference image to show, not just tell, our AI what you want. This principle can be seen across many popular AI image apps such as Playground and KREA and eventually inspired us to create an AI-first Photoshop in Vispunk.
We can go one step further and not require text inputs at all. For Pebblely, we understand that not everyone is familiar with writing prompts. So we "packaged" prompts into themes, which users can use with a click. This not only makes it easier for users to use Pebblely but also increases the likelihood they get good results.
But non-text-box interfaces are not limited to image generation. As an example, it's easier to drag a slider to change a scale than to describe a scale point on a scale (e.g. 2 out of 10). Folks like Geoffrey Litt and Linus Lee have done many explorations into AI interfaces beyond the text box. There are also many interesting concepts from the popular AI UI/UX demo day in San Francisco.
My takeaway: Think beyond text
Text is not always the most efficient way to instruct an AI. A text box is not always the best way to interact with an AI. Consider other inputs and interfaces that can help users better describe or indicate what they want.
Besides in the inputs, how we design and display the outputs matters too.
2. One result vs multiple results
Until AI can read our minds, even when we give our best input, we would still sometimes get the wrong or undesirable results. For a chat interface like ChatGPT, the user can ask follow-up questions to refine the answer. For an image generator like Pebblely, the user can generate another image.
But we learned that users might not always be patient enough to generate another image. Once they get one bad image, they might immediately dismiss our app as terrible. This is likely why apps like Midjourney generate four results each time. For Pebblely, we went as far as letting users generate up to 10 images each time. Having multiple results, instead of one, increases the chances that the user gets a satisfactory result.
Satisfaction can be measured in two dimensions:
- Adherence: How much does it follow the user’s prompt? A prompt, such as “a bottle on a beach”, can be interpreted in multiple ways. Providing multiple results makes it more likely for at least one result to match the user’s intention.
- Quality: For images, how nice or realistic is the image? For text, how accurate or correct is the answer? Since AI outputs are, to a certain extent, random, having more outputs makes it more likely to include a desired result.
But the context matters. Users can go through multiple generated images or short text (e.g. product descriptions or code snippets) easily. But if they are chatting with your AI, they probably would not want multiple responses every time.
My takeaway: Aim to provide a satisfactory result on the first attempt
The ideal is to give users the best and correct result on their first try.
But that is not always possible because (1) there might be not one right result for something creative like images and (2) your AI might not be able to give the best and correct answer either because of the AI's limitations or the vagueness of the user's input. In that case, providing multiple results for each generation might work better.
As an aside, many AI tools would ask for feedback on the generated results, in hope to improve their AI models and future results. But this improvement process is not as automated and immediate as say a social media's algorithms. Just because you downvote a ChatGPT response does not mean you will get a better result for your next question. It requires the company to retrain or re-finetune their AI models, usually with more or better data, and then re-evaluate the new AI models. Also, a common misconception is that we use our users' generated images to improve our AI models. This would not work because we would be feeding our AI models with artificial images rather than real photos, which would make the results more artificial rather than photorealistic.
Next, we have to consider how many credits, if any, to deduct for generating results.
3. Limited vs unlimited credits
When thinking about credits in AI tools, I’m reminded of first-person shooter games. If you have unlimited bullets, you will feel unrestricted and fire away at every sign of enemies. But if you have limited bullets, you will be more conservative and aim carefully before firing. I believe AI tool users feel and act the same way.
In Pebblely, generating an image consumes one credit regardless of whether the user downloads the image. This has annoyed many users who have limited credits (either 40 on the free plan or 1,000 on the $19/month plan). Why is it using up my credits even when I'm not downloading the generated images?! In case you are curious, one reason is that generating every image uses our expensive GPUs (more on this next); hence it is common in the space to charge users for every generation.
Most AI products with limited credits, including ours, would show a credit countdown. You might think this is a tiny, trivial, of-course-you-need-it design. But it has implications for the user experience. A credit countdown creates anxiety. It's like being at the carnival with fewer and fewer tokens. ChatGPT and Midjourney have interesting designs around this. ChatGPT gives free users limited usage of GPT-4o. Instead of a countdown, ChatGPT simply switches to GPT-3.5 until the limit resets. For Midjourney, you have to type a command to see your remaining credits, which I suspect removes some of the anxiety while generating images. Interestingly, Midjourney does not even use the concept of credits but rather GPU hours. I’m not sure if it is intentional to make the limit feel less understandable or easy to calculate and hence feel less restrictive.
The opposite of limited credits is, well, unlimited credits. Most funded startups (e.g. Jasper, Notion) offer that. If you are bootstrapped, you want to calculate the potential cost if users make good use of the unlimited credits (because some definitely would). We have a few extreme customers on our unlimited plan, who generated more than 20,000 images in a month. That said, without an unlimited plan, they might not have generated that many images.
There are also a few in-betweens:
- Limit and unlimited: Midjourney offers limited fast generations and unlimited slow generations. ChatGPT offers limited GPT-4o responses but unlimited GPT-3.5 responses. This is a good way to provide unlimited generations so that users would keep using your app while offering premium experiences such as faster generation or better results so that users would upgrade.
- Pay-per-result: Intercom charges per AI resolution, on top of the regular subscription price. This works well because the incentives are aligned; Intercom would want to make sure their AI resolves their customers' customer tickets well and Intercom's customers only pay when that happens. But this is not suitable for every AI product or feature. I wouldn't want to pay Linear for every duplicate issue detected by their AI.
My takeaway: Offer unlimited credits if you can; charge for each if you can
Consider the feeling you want your users to have while using your app. Unlike games, it’s not as fun to have to conserve your credits while trying to get your work done. But you also have to make sure your business model supports the number of credits you want to offer.
A big part of whether your business model can support your credit plans is your cost structure. Let’s go through that next.
4. API vs self-hosted models
Many AI apps are using APIs, such as OpenAI’s and Stability's. That is reasonable since such APIs offer best-in-class AI models and are easy to use. But while they might seem cheap, the cost can add up quickly. For instance, we have generated more than 23 million images for our users. Assuming it costs "only" $0.03 to generate each image, that would have cost us almost $700,000. This bag of cash can fund most startups for several years.
Instead, we opted to train custom models and host them on AWS (which kindly gave us $150,000 credits). This changed our cost structure from a variable cost (e.g. $0.03 per image) to a step-fixed cost (e.g. $1,000 per month per reserved GPU instance). You can also get steep discounts if you get the instances for one to two years. But that can be a huge commitment for most startups, which might not be around a year later. While it’s possible to resell the instances on AWS’s marketplace, we realized the market is not that liquid.
My takeaway: Host your models if they perform better than APIs
Host your models if you can train new models or finetune existing models and get comparable or better results than using APIs—especially if your models are part of your differentiation. Defog finetuned CodeLlama to create their text-to-SQL model; Playground trained their foundation image models.
That being said, most startups, especially those without AI engineers, should probably use APIs, given how advanced they are and how expensive it can be to train or finetune models.
Now that we have covered single results vs multiple results and GPUs, I want to talk about serial and parallel generations.
5. Serial generation vs parallel generation
This only applies to AI products that generate multiple results each time.
Midjourney takes about a minute to generate each image, which is a long time. In comparison, Pebblely takes five seconds. But Midjourney smartly generates four images simultaneously and you can run up to 12 concurrent jobs. Then overall, it would feel like each image didn’t take too long to be generated (even when physically it did).
An advantage of using an API is that most allow you to do such parallel generations, up to the rate limit of your plan. If you are self-hosting your model, the number of GPU instances you have is essentially your rate limit (unless you can process more than one generation per GPU). Even if you can process 10 generations simultaneously with 10 GPUs, you might not want to do that. Because if one user makes 10 generations simultaneously, every other user who wants to generate would have to wait until one of your GPU instances is freed up from the initial request.
Again, it’s a balance. If you have 10 GPU instances, each generation is pretty fast (2-3 seconds), and not many users would be generating at the same time, you could afford to generate a few results in parallel without jamming the queue.
My takeaway: Use parallel generation to make generations feel faster
The best is if you can speed up your individual generations.
But if you cannot and each generation takes a long time, use parallel generation to give the feeling of faster generations. (Of course, this is provided that you can afford enough GPUs. There are also technical design considerations, such as how to handle your queue system, which are beyond the scope of this essay.)
It depends!
While I have included many examples to make my points, there are probably AI products doing the opposite and doing just fine. If you know of them, let me know.
Also, what AI experience design lessons have you learned from building AI products and features?
Recent essays
- 2026·07·07
- 2025·09·11
- 2025·08·07